Passionate about Data Science and AI, I graduated in 2023 with a Master’s degree in Data Science at the Université de Rouen. During my studies I’ve specialised myself in Medical Image Analysis with projects focusing on the classification and segmentation of medical images using deep learning models. These projects were also about training transformer models with small datasets and the effect of Data Augmentation and Transfer learning. After my Master’s degree, I worked as a Research Assistant in PURRlab at the IT University of Copenagen and in the MICS laboratory at CentraleSupélec Paris on the robustness of AI in healthcare and the study of public medical datasets in research papers. I am now a PhD Student in PURRlab working on the evaluation of machine learning algorithms and data quality.
September 2025 - Current
Copenhagen (Denmark)
September 2025 - Current
April 2025 - September 2025
Gif-sur-Yvette (France)
April 2025 - September 2025
October 2023 - January 2025
Copenhagen (Denmark)
October 2023 - January 2025
January 2024 - July 2024
October 2023 - Dec 2023
April 2023 - September 2023
Illkirch-Graffenstaden (France)
April 2023 - September 2023
April 2021 - July 2021
Vannes (France)
June 2021 - July 2021
April 2021 - June 2021
2021-2023 Master Data Science and Engineering (SID)Grade: 16.215 out of 20 (Valedictorian, Graduated with Highest Honors) | ||
Université de Rouen2020-2021 Bachelor's degree in Computer Science and Data ScienceGrade: 14.958 out of 20 (Valedictorian, Graduated with Honors) | ||
IUT de Vannes2018-2020 2 years diploma in Computer scienceGrade: 13.835 out of 20 |
The diversity of training datasets is usually perceived as an important aspect to obtain a robust model. However, the definition of diversity is often not defined or differs across papers, and while some metrics exist, the quantification of this diversity is often overlooked when developing new algorithms. In this work, we study the behaviour of multiple dataset diversity metrics for image, text and metadata using MorphoMNIST, a toy dataset with controlled perturbations, and PadChest, a publicly available chest X-ray dataset. We evaluate whether these metrics correlate with each other but also with the intuition of a clinical expert. We also assess whether they correlate with downstream-task performance and how they impact the training dynamic of the models. We find limited correlations between the AUC and image or metadata reference-free diversity metrics, but higher correlations with the FID and the semantic diversity metrics. Finally, the clinical expert indicates that scanners are the main source of diversity in practice. However, we find that the addition of another scanner to the training set leads to shortcut learning.
Motivated by the strong performance of CLIP-based models in natural image-text domains, recent efforts have adapted these architectures to medical tasks, particularly in radiology, where large paired datasets of images and reports, such as chest X-rays, are available. While these models have shown encouraging results in terms of accuracy and discriminative performance, their fairness and robustness in the different clinical tasks remain largely underexplored. In this study, we extensively evaluate six widely used CLIP-based models on chest X-ray classification using three publicly available datasets: MIMIC-CXR, NIH-CXR14, and NEATX. We assess the models fairness across six conditions and patient subgroups based on age, sex, and race. Additionally, we assess the robustness to shortcut learning by evaluating performance on pneumothorax cases with and without chest drains. Our results indicate performance gaps between patients of different ages, but more equitable results for the other attributes. Moreover, all models exhibit lower performance on images without chest drains, suggesting reliance on spurious correlations. We further complement the performance analysis with a study of the embeddings generated by the models. While the sensitive attributes could be classified from the embeddings, we do not see such patterns using PCA, showing the limitations of these visualisation techniques when assessing models.
Datasets play a critical role in medical imaging research, yet issues such as label quality, shortcuts, and metadata are often overlooked. This lack of attention may harm the generalizability of algorithms and, consequently, negatively impact patient outcomes. While existing medical imaging literature reviews mostly focus on machine learning (ML) methods, with only a few focusing on datasets for specific applications, these reviews remain static – they are published once and not updated thereafter. This fails to account for emerging evidence, such as biases, shortcuts, and additional annotations that other researchers may contribute after the dataset is published. We refer to these newly discovered findings of datasets as research artifacts. To address this gap, we propose a living review that continuously tracks public datasets and their associated research artifacts across multiple medical imaging applications. Our approach includes a framework for the living review to monitor data documentation artifacts, and an SQL database to visualize the citation relationships between research artifact and dataset. Lastly, we discuss key considerations for creating medical imaging datasets, review best practices for data annotation, discuss the significance of shortcuts and demographic diversity, and emphasize the importance of managing datasets throughout their entire lifecycle. Our demo is publicly available at http://inthepicture.itu.dk/.
The development of larger models for medical image analysis has led to increased performance. However, it also affected our ability to explain and validate model decisions. Models can use non-relevant parts of images, also called spurious correlations or shortcuts, to obtain high performance on benchmark datasets but fail in real-world scenarios. In this work, we challenge the capacity of convolutional neural networks (CNN) to classify chest X-rays and eye fundus images while masking out clinically relevant parts of the image. We show that all models trained on the PadChest dataset, irrespective of the masking strategy, are able to obtain an Area Under the Curve (AUC) above random. Moreover, the models trained on full images obtain good performance on images without the region of interest (ROI), even superior to the one obtained on images only containing the ROI. We also reveal a possible spurious correlation in the Chaksu dataset while the performances are more aligned with the expectation of an unbiased model. We go beyond the performance analysis with the usage of the explainability method SHAP and the analysis of embeddings. We asked a radiology resident to interpret chest X-rays under different masking to complement our findings with clinical knowledge.
Medical Imaging (MI) datasets are fundamental to artificial intelligence in healthcare. The accuracy, robustness, and fairness of diagnostic algorithms depend on the data (and its quality) used to train and evaluate the models. MI datasets used to be proprietary, but have become increasingly available to the public, including on community-contributed platforms (CCPs) like Kaggle or HuggingFace. While open data is important to enhance the redistribution of data’s public value, we find that the current CCP governance model fails to uphold the quality needed and recommended practices for sharing, documenting, and evaluating datasets. In this paper, we conduct an analysis of publicly available machine learning datasets on CCPs, discussing datasets’ context, and identifying limitations and gaps in the current CCP landscape. We highlight differences between MI and computer vision datasets, particularly in the potentially harmful downstream effects from poor adoption of recommended dataset management practices. We compare the analyzed datasets across several dimensions, including data sharing, data documentation, and maintenance. We find vague licenses, lack of persistent identifiers and storage, duplicates, and missing metadata, with differences between the platforms. Our research contributes to efforts in responsible data curation and AI algorithms for healthcare.
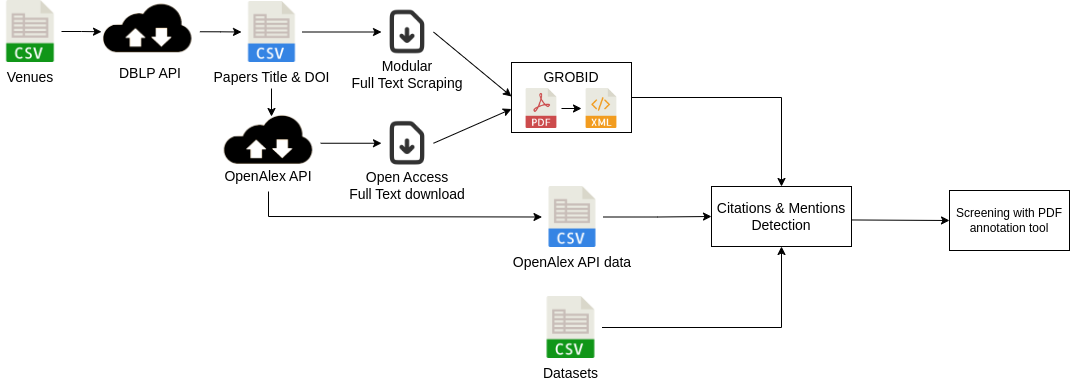
Medical imaging papers often focus on methodology, but the quality of the algorithms and the validity of the conclusions are highly dependent on the datasets used. As creating datasets requires a lot of effort, researchers often use publicly available datasets, there is however no adopted standard for citing the datasets used in scientific papers, leading to difficulty in tracking dataset usage. In this work, we present two open-source tools we created that could help with the detection of dataset usage, a pipeline using OpenAlex and full-text analysis, and a PDF annotation software used in our study to manually label the presence of datasets. We applied both tools on a study of the usage of 20 publicly available medical datasets in papers from MICCAI and MIDL. We compute the proportion and the evolution between 2013 and 2023 of 3 types of presence in a paper: cited, mentioned in the full text, cited and mentioned. Our findings demonstrate the concentration of the usage of a limited set of datasets. We also highlight different citing practices, making the automation of tracking difficult.
In this work, we focused on deep learning image processing in the context of oral rare diseases, which pose challenges due to limited data availability. A crucial step involves teeth detection, segmentation and numbering in panoramic radiographs. To this end, we used a dataset consisting of 156 panoramic radiographs from individuals with rare oral diseases and labeled by experts. We trained the Detection Transformer (DETR) neural network for teeth detection, segmentation, and numbering the 52 teeth classes. In addition, we used data augmentation techniques, including geometric transformations. Finally, we generated new panoramic images using inpainting techniques with stable diffusion, by removing teeth from a panoramic radiograph and integrating teeth into it. The results showed a mAP exceeding 0,69 for DETR without data augmentation. The mAP was improved to 0,82 when data augmentation techniques are used. Furthermore, we observed promising performances when using new panoramic radiographs generated with inpainting technique, with mAP of 0,76.
The U-Net model, introduced in 2015, is established as the state-of-the-art architecture for medical image segmentation, along with its variants UNet++, nnU-Net, V-Net, etc. Vision transformers made a breakthrough in the computer vision world in 2021. Since then, many transformer based architectures or hybrid architectures (combining convolutional blocks and transformer blocks) have been proposed for image segmentation, that are challenging the predominance of U-Net. In this paper, we ask the question whether transformers could overtake U-Net for medical image segmentation. We compare SegFormer, one of the most popular transformer architectures for segmentation, to U-Net using three publicly available medical image datasets that include various modalities and organs with the segmentation of cardiac structures in ultrasound images from the CAMUS challenge, the segmentation of polyp in endoscopy images and the segmentation of instrument in colonoscopy images from the MedAI challenge. We compare them in the light of various metrics (segmentation performance, training time) and show that SegFormer can be a true competitor to U-Net and should be carefully considered for future tasks in medical image segmentation.
Pipeline to study the ability of a CNN model to classify images without the region of interest in medical images and evaluate potential bias/shortcuts in datasets
Pipeline to detect dataset presence in research papers
Web APP to annotate PDF File. The files can be annotate by multiple users for up to two initial sets of labels.
Website multiple API such as OpenAlex to search for papers referencing another one and papers matching keywords and concept.
Comparison of Segformer and U-Net to perform semantic segmentation on the CAMUS dataset (cardiac ultrasound images).
Classification of eye fundus images for glaucoma detection with convolutional neural network.
Analysis of a dataset on the 2011-2012 season of the Premier League.
Development of an astronomical observation website with React-Flask-MongoDB.
Development of a website and a mobile application for sports management with React/React Native.